Autoregressive schemas

LLMs are good at producing structured output from messy input. That property is core to agentic systems and to tasks like structured data extraction. Both are work I do day to day, at my job and on side projects. A good prompt goes a long way, but how much does the output schema itself matter?
I started looking at this because of a class of failure I kept hitting. The output would be locally fine, every field reasonable on its own, but globally broken. I ran into it doing structured data extraction from financial documents on another project, and I ran into it again on a personal side project at madejustfor.me that generates personalized story-game adventures for kids. Different domains, but the failures looked similar, so I wanted to understand why.
The eel
Here's a level the side project produced for an underwater dungeon. The relevant encounter:
{
"location": "Murky Trench",
"enemy": {
"name": "Bio-luminescent Eel",
"weakness": "Tainted Kelp"
},
"pickup": {
"name": "Abyssal Core",
"effect": "Stabilizes pressure"
},
"trigger": "Eel carcass blocks the path to the ancient gate"
}The player defeats the eel and the eel's corpse blocks the path forward. Defeating the enemy creates the obstacle instead of removing it. The pickup from this encounter is the item needed for the final boss, so the player has done all the work and is now soft-locked behind a fish they killed. Each field is reasonable in isolation, but the level is broken.
Why the schema order matters
The model is generating left to right, one field at a time, and each field is conditioned on every field before it. Once "Bio-luminescent Eel" is committed to the output, the trigger field has to say something consistent with there having been an eel. The cheapest continuation that references the eel is the eel itself, which by this point in the output is dead, so the carcass becomes the obstacle.
The model didn't reason about whether defeating an enemy should produce a blockage. It produced tokens that locally fit the field name and locally referenced what it had just written. That's how autoregressive generation works. The schema isn't a shape that gets filled in, it's a sequence of fields generated in order, and each field constrains what later fields can plausibly say. Field order is part of the prompt whether you intended it that way or not.
This is true whether the model is producing freeform JSON or generating under a forced schema like Gemini's structured output mode, which is what I was using. Constrained decoding makes the argument sharper, not weaker: the schema is literally part of the decoding loop, walking the model through fields in the order you defined.
The fix is to put fields in an order that mirrors how a person would make the decisions. Setting and theme before specific entities, premise before consequences, anchors first and dependents later. An incident report would start with what happened before listing root cause. A meeting summary would establish purpose before action items. The pattern is the same: commit to the things that frame everything else first, then let later fields depend on them. When the model commits to "the path forward is sealed by ancient magic" before it commits to "the enemy is an eel," the trigger has somewhere to go that isn't the eel's corpse.
A small experiment
I built a testbed to measure this. The model generates a video game level from a short input premise, with the same fields available across all six schema variants. I used Gemini 3.1 Flash Lite with no thinking budget because that's what the side project runs on. I judged each output on a six-criterion rubric using Claude Sonnet 4.6 with extended thinking, across 64 input cases per variant.
The six variants I tested, each representing a way schemas actually get organized in the real world:
- a flat list - like API query parameters or a database table
- by type - numbers together, then dates, then strings, etc
- appended over time - fields are just added to the end as the schema evolves over time
- the ui contract - ordered to match the UI the API was built for
- alphabetic ordering - maybe with some reasonable structure, but hit by an auto-formatter
- a decision structure - organizes so that decisions come before downstream consequences
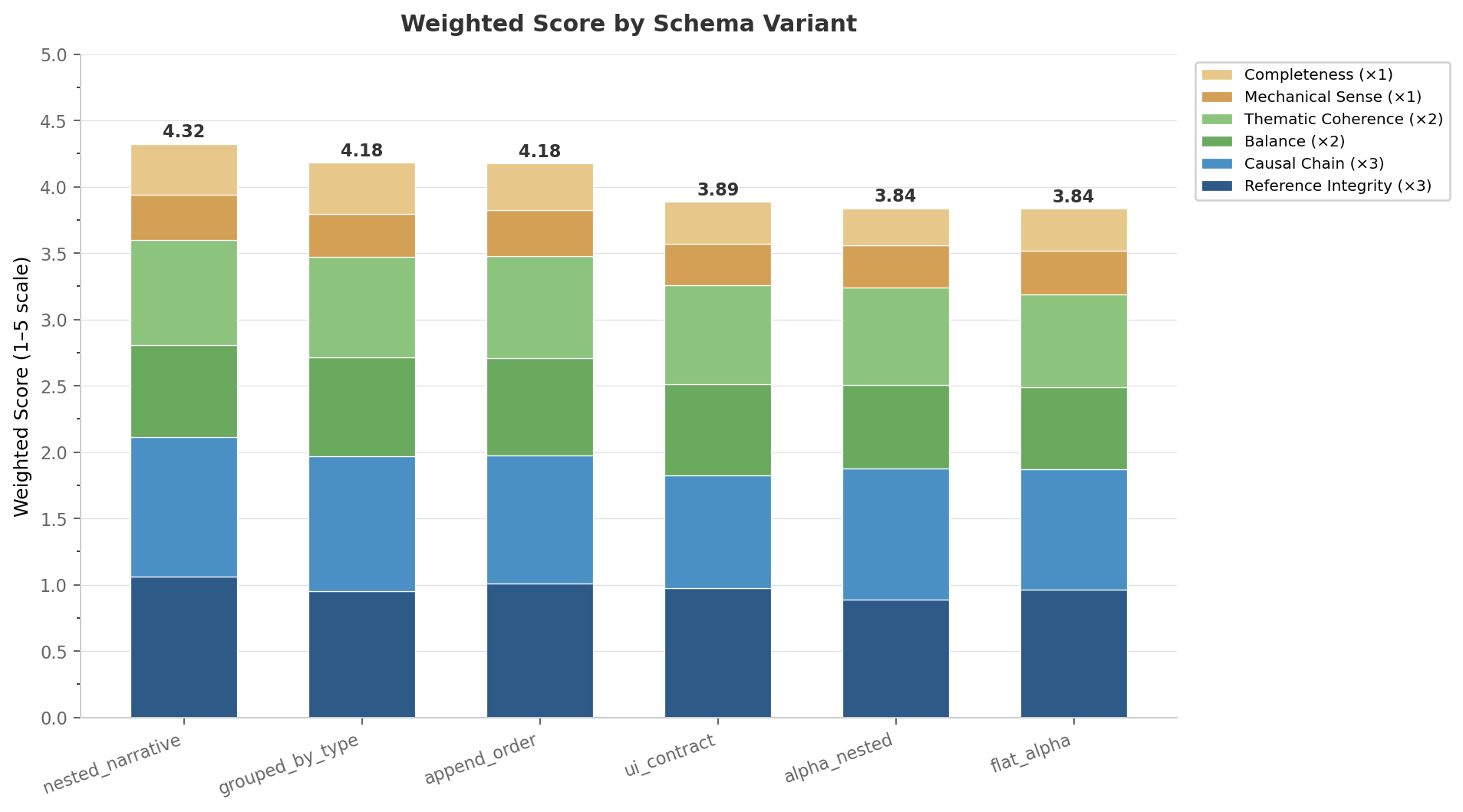
The decision-ordered schema came out on top. The gap between best and worst was 0.49 points on a 5-point rubric, and the decision-ordered schema beat each of the worse-ordered ones in 70 to 75 percent of paired comparisons on the same input. The gains show up mostly on reference integrity, causal chain, and thematic coherence, which are the criteria most affected by whether later fields stay consistent with earlier ones, exactly where you'd expect autoregressive conditioning to bite. Numbers, raw outputs, and the striking individual cases are in the repo: https://github.com/jdhornsby/autoregressive-schemas.
When to care
Most CRUD-style tool schemas don't have this problem. If your tool takes independent parameters from a clear instruction like get_user(user_id, include_email), there's no consistency pressure between fields and not much for schema order to do.
The failure mode shows up when you ask the model to construct something coherent: plans whose steps depend on each other, tickets where reasoning fields have to match the decision, configs whose later fields have to be consistent with earlier ones, reports that synthesize multiple inputs into a structured artifact. These are the kinds of tools that make agents useful, and they're the cases where field order actually shows up.
Whether to care depends on two things: whether the model has to keep multiple fields mutually consistent, and whether you're running at a scale or cost ceiling where you can't just throw a bigger model or thinking budget at the problem. If both apply, schema design is worth thinking about. The same logic applies when wrapping an existing REST API as an MCP tool: you inherit a field ordering that was designed for human ergonomics, database normalization, or backward compatibility, and none of those are what helps an LLM generate good output. Whether it actually matters in any given case is an empirical question, and the cheap way to find out is to look at your own outputs for the pattern the eel illustrates.
Scope and limits
This was one model, one task, dense field interdependencies, minimum thinking. Tasks with weaker dependencies probably show smaller effects. Bigger models and thinking budgets compensate for a poorly-ordered schema, but you pay for it. Prompting and fine-tuning are bigger levers than schema design; schema design is a smaller one that costs nothing additional at inference time. Two follow-ups in progress, both separate posts: how thinking budget compensates for poor schema order, and whether the effect replicates on other small models without thinking.



